In the early days, your app runs with a single PostgreSQL or MySQL instance. But as it grows, it’s a common practice to add a database replica to reduce the load from the primary database instance. This is so-called Single-leader replication.
All write queries would still go to the primary database, but read-only queries can be served from the replica (or multiple replicas). We’ll use PostgreSQL as an example. It’s common in the industry to call these database instances “PostgreSQL writer” and “PostgreSQL reader”.
Now, how do you determine which queries would go to reader and which queries would go to writer? If you have some kind of Reports feature in the application, it makes sense to execute all reporting-related queries on PostgreSQL reader (assuming that reporting produces heavy read-only queries).
However, sending a subset of queries to the reader may still be not enough to reduce load from the writer. What if we send all read-only queries (basically, all SELECTs) to the reader, and let the writer only deal with writes?
The plan sounds doable in theory. Now, let’s zoom out to see how the replication between the writer and the reader works.
All writes that come to the writer instance are appended to the Postgres’ Write Ahead Log (WAL). That way, the reader instance can consume updates from writer’s WAL and apply them to local replica. It’s also common to have multiple replicas - in this case, all these readers would consume WAL from the writer.
MySQL is using the same replication principle. There’s a binary log instead of WAL, which all readers consume from the writer.
With this replication design, we must know about possible issues. What happens if there’s a network blip between the writer and the reader? The reader wouldn’t be able to consume the latest updates from the writer and it would get delayed. Also, whenever your application produces too many writes, the reader may get delayed again. A delayed database replica will cause stale reads.
This becomes an issue when we are going to send all read-only queries to the reader. Imagine this flow:
POST /kittens
> INSERT INTO kittens ...
> redirect_to created_kitten
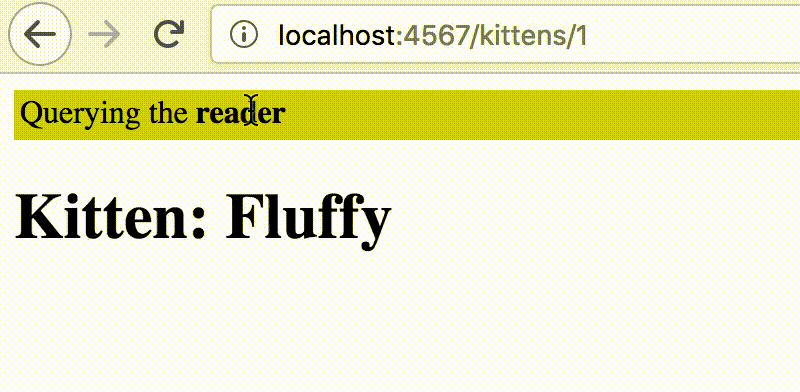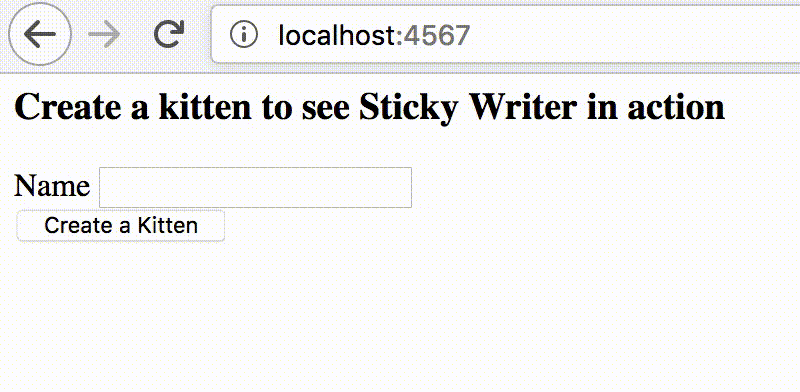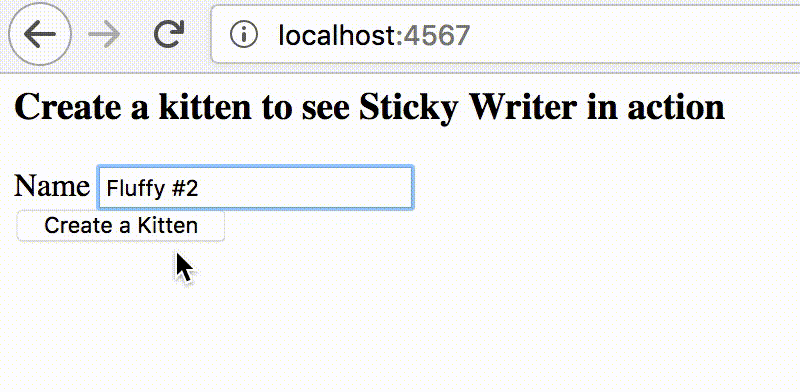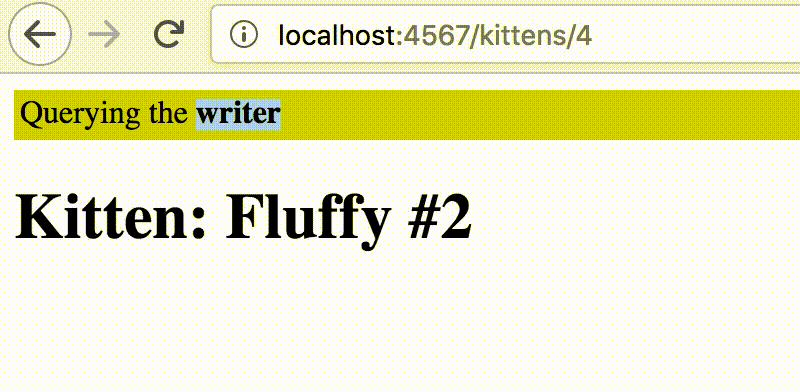
GET /kittens/1
> SELECT * FROM kittens WHERE id=1In the first request, the INSERT would go to the writer. In the second request, we would send the SELECT to reader since it’s a read-only query.
Somewhere between these two requests, the newly inserted row would be replicated from the writer to the reader. By the time when the client hits the reader in the second request, the newly inserted row would usually be present in that instance.
However, when the replication is delayed by even a bit, the second request will respond with HTTP 404 because that newly inserted row will not be replicated to the reader yet. We’ve run into a stale read.
This becomes a major problem for us as we want to send as many queries as possible to the reader.
Sticky Writer
A common solution to this problem used in the industry is so-called “stickiness”. The idea is to send the read-only query to the writer, if we know that a client recently performed a write. If the client didn’t perform any writes, we are safe to send their query to the reader.
In this post, I’ll show how you can implement the stickiness in only 50 lines of code. I stumbled upon this pattern at Shopify but I didn’t fully understand it, which made me write this post to learn how it works.
In the example, I’m going to use pg driver to work with PostgreSQL from Ruby and Sequel as a simple ORM.
We start from setting up two PostgreSQL instances: a writer and a reader. Check out this script that configures the replication and starts two PostgreSQL processes (writer and reader).
Now we can initialize Sequel with two connections (writer and reader):
DB = Sequel.connect("postgres://localhost:#{POSTGRES_PORT}/sticky-pudding",
servers: {
replica: { port: POSTGRES_PORT + 1 }
}
)And the Sinatra route to create kittens:
post "/kittens" do
DB.transaction do
record = Kitten.create(
name: params["kitten"]["name"]
)
response.set_cookie(:sticky_writer, value: "1", expires: Time.now + STICKY_TIMEOUT)
redirect "/kittens/#{record.id}"
end
endThe trick is to send the client a cookie that works as a flag for Sticky Writer. The presence of the cookie would mean that the client recently performed a write, and that the app should use writer even for read-only queries. Another benefit of using cookie is that it automatically expires (in my example, in 10 seconds). We set the expiry because we use 10 seconds as a maximum delay of the reader. After that period, we expect the value to be replicated even if the reader experienced a short delay.
get "/kittens/:id" do |id|
if cookies[:sticky_writer]
@target_db_server = :default # writer
else
@target_db_server = :replica # reader
end
@kitten = Kitten.server(@target_db_server).first(id: id)
erb :show
endIn the this route, we check for the auto-expiring cookie to determine the target connection. And then Sequel allows us to enforce the connection for a query.
To see how it works in action, clone the sample repo and run steps described in the README. Here is a little preview:
Cookie vs other storage
What if your client is an API consumer that doesn’t support cookies? Another way to store the stickiness would be to set a flag in Memcache or Redis. Instead sending a cookie, you would set a flag in the key/value store with the session id as a part of the key.
We want to include the session id as a part of the key to isolate stickiness flags between different clients. In that case, a write performed by one client won’t affect stickiness of other clients.
Scoping stickiness flag
One way to scope stickiness is per session or client. In a multi-tenant app, you can also scope it to the tenant. In fact, that’s what we do at Shopify, which is a multi-tenant platform.
Wrapping up
I hope this post helped you to learn about replication in modern databases and how it’s used to scale applications. You also learned about replication delay and Sticky Writer as a possible solution to the problem.
When your app starts to get more and more traffic, it’s common to add database replicas. With a pattern like Sticky Writer, you are safe to send as many read-only queries as possible to those replicas.
An alternative to Sticky Writer is to keep track of WAL position and use the position to determine whether to query reader or writer. This solution is very well described in a post by Brandur. If you’re interested in the topic, I’d recommend you to read it to see how an alternative approach can be designed.
If you wonder if there’s an existing implementation of Sticky Writer for Rails apps, have a look at the makara gem.
For the further reading, I can recommend the Designing Data-Intensive Applications book by Martin Kleppmann. It covers all topics related to scaling databases, including replication strategies and sharding.
