Have you ever wondered what happens with a running background job in Sidekiq or Resque when you deploy new version of code and restart the workers? The answer depends on what library you use and sometimes the behaviour is not acceptable for the business needs.
My post is an overview of architecture concerns that I've been keeping in mind when designing continuous deployment of a highly distributed background job system.
First of all, how does Resque and Sidekiq work
Sidekiq: when the worker receives SIGTERM (graceful shutdown signal), it lets the job to finish with a certain timeout (8s by default). If the job didn't finish within the timeout, it's killed and re-enqueued to be retried in the future.
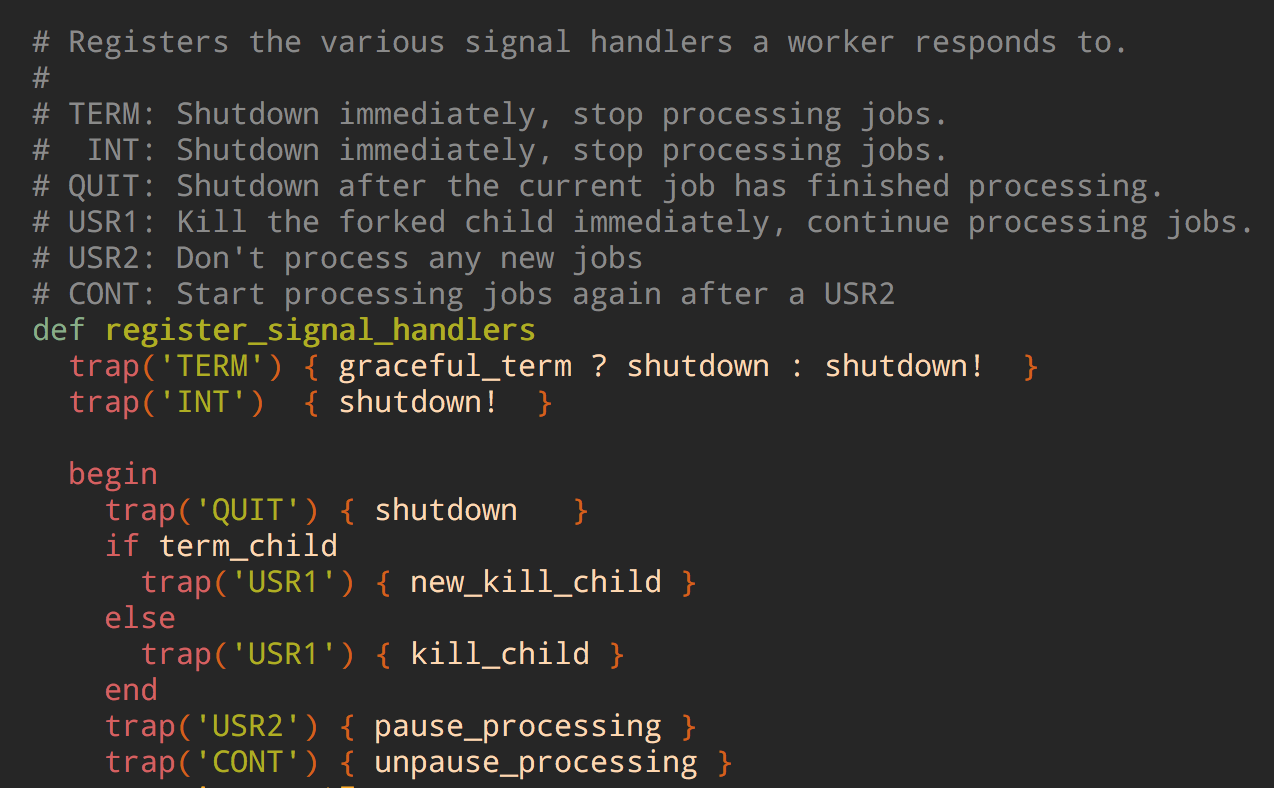
Resque: on SIGTERM or SIGQUIT (graceful shutdown signals for Resque) it stops taking new jobs from the queue and waits until the current job has finished processing. There's no timeout for long-running jobs.
Problems
The problem with Sidekiq is that if you deploy and restart workers too frequently and your jobs are too long to complete, there might the the case when you deploy every hour and the job that takes few hours won't ever finish. It would eventually be started and killed multiple times during the workday, and maybe it will have enough time to run during the night when you don't deploy. Sidekiq also requires your jobs to be idempotent (means that your job can safely execute multiple times), which is the best practice not always achievable in the real life.
The issue with Resque is that it has no timeout for graceful shutdown. What if you sent SIGTERM but the current job is going to take five more hours to finish? What if it has infinite loop that runs forever?
In cloud environments like Heroku there's a platform-wide timeout for graceful termination. For instance Heroku sends SIGTERM and then waits 10 seconds for process to exit (upd: the timeout was increased to 30 sec). If the process didn't exit, Heroku will kill it in the hard way.
Neither behaviors (Sidekiq and Resque) are ideal. You have to choose between tradeoffs based on what approach is less evil for your business.
At Shopify we have the world's biggest Rails app with hundreds of jobs. Some of them take seconds and some take weeks to complete. The Sidekiq's approach wouldn't work for us because these long-running jobs would just never ever complete due very frequent deploys. As Resque users we've allowed jobs to take as much time as they want, doesn't matter if they have to be restarted. From time to time we found job workers that have been stuck forever and we had to manually kick them off.
Our architecture with workers that restart only when they finish the current job (which may happen only in 10 days) makes it really hard for us to migrate to cloud environments which:
-
have restrictions for how long the process can gracefully terminate
-
encourage to write software in a way that any unit of work can be interrupted at any time
-
discourage units of works that are unsafe to terminate, such as long-running jobs
Alternatives
We can no longer give the job unlimited time to finish and at the same time we can't simply terminate and re-enqueue the job because deploys are too frequent and the job may not manage to finish in the window between the deploys. What are the options?
One option is to increase the platform timeout for graceful termination. In Kubernetes you can use terminationGracePeriodSeconds to allow the container to stay in termination state for days or weeks. When I started experimenting with it, it turned out that the option was half broken (maybe I was the only person who used it?). Another problem with increasing timeout is that it's a hack, and even high value doesn't guarantee that Kubernetes won't kick out the container earlier.
Another option is to make the jobs resumable. The main reason why a job would take days to complete is the amount of records that it has to touch. SyncProductsJob may work fast for a customer with a dozen products but stuck for a week for your largest customer. So why don't we save the job progress (the fact that it already processed N records), allow to kill and re-enqueue the job on restart, and resume the work from the point when it was interrupted.
You can check my prototype of this idea. What I love about it is that it works with any enumerable collection which can be ActiveRecord scope or a large CSV.
Lessons learned
First of all, don't let your developers write non-indempotent jobs that are unsafe to interrupt. Keep an eye on long-running jobs and rewrite those that are taking too long. Always prefer many smaller jobs to one large job. There's no overhead of enqueueing a new job.
Celery, a job processing framework in Python, provides an option to limit the max time that a job can take. I think it's a great constraint to have as it could help to keep your jobs runtime healthy, in the same manner with request timeout in HTTP servers.
Summary
Today I'm working on generic API for resumable/interruptible jobs which would help us to move towards cloud environment where it would be safe to shutdown or restart any background job worker. The main goal of the API would be to make developer define the collection of items to process (records in the database or CSV rows) and the work to be done with each record.
If the API turns our to be successful I'll probably share it publicly. Ping me if you're have any ideas or if you would like a sneak peek of the API.
