
Every time when you deploy code with schema changes, you have to apply new Active Record migrations by running bin/rails db:migrate. This is a common step of deploy scripts (see Capistrano).
While running migrations as a part of the deploy is the default approach used by most of companies, for some reason Rails community never reconsidered alternatives. Does it bring extra complexity to the release process?
- If a migration fails, should it fail and revert the deploy?
- If you want to revert, new code would run in production for a limited time before the migration failed. That could cause even more issues when you roll back.
- If you use more that one database (maybe you use sharding), you have to apply the migration to each database
- If a migration takes longer (hours), it blocks the deploys from finishing
- What if the actor who runs the migration lost SSH connection?
- In cloud environments (Heroku, Kubernetes), there may be no “after deploy” hook to run the migrations
This post describes how we can shave off the migrations part from the deploy process. What we came to at Shopify is asynchronous migrations that are eventually applied after a deploy and controlled by humans.
How does that work?
First we need to understand what db:migrate really does.
If we look at Active Record Rake tasks, we’ll find a call to ActiveRecord::Base.connection.migration_context.migrate. That has to be the entry point to run migrations. When it’s invoked with no arguments (like ENV['VERSION']), MigrationContext#migrate creates a MigrationProxy instance for each migration class and calls Migrator.new.migrate.
Now we understand how migrations are invoked, and we can try to redesign the process to make it asynchronous and stop running migrations as a part deploy. What if instead we’d run the migration from a background job?
Each time there is a pending migration, we would push a background job that would apply the actual migration and report the result. Let’s see how this could be implemented.
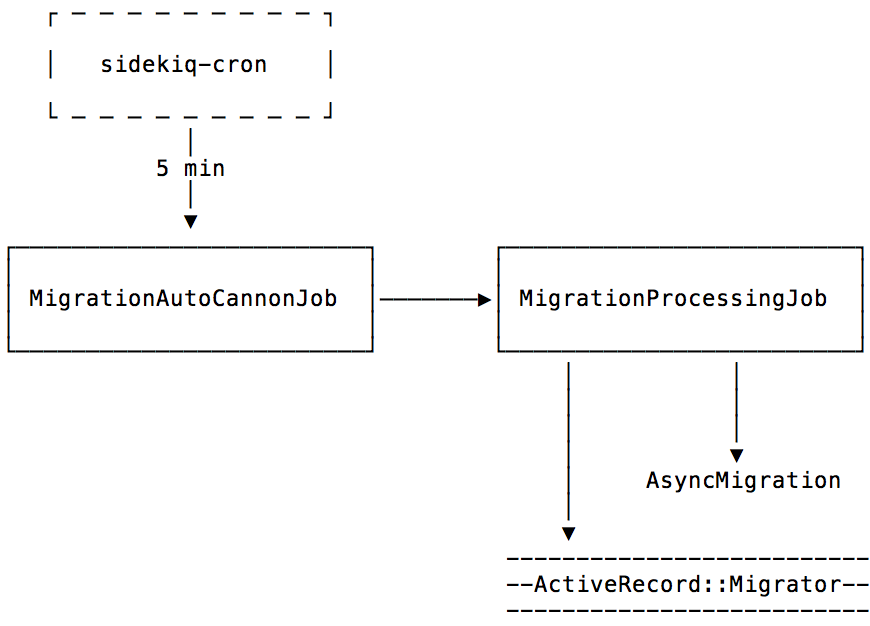
First, we need to schedule a recurring job (with a tool like sidekiq-cron) that would run every few minutes and check for pending migrations.
class MigrationAutoCannonJob < ApplicationJob
def perform
return unless migration_context.needs_migration?
pending_migrations = (migration_context.migrations.collect(&:version) - migration_context.get_all_versions)
# run them!
end
private
def migration_context
ActiveRecord::Base.connection.migration_context
end
endWe must remember than running a migration is a blocking process - we can’t run the next migration before the previous one finished. We also want to be able to monitor the state of running migrations, so let’s create an ActiveRecord model to keep track of it.
$ rails generate model async_migration version:integer state:text
# app/models/async_migration.rb
class AsyncMigration < ApplicationRecord
end
# don't forget to add unique indexes!Now let’s update our recurring “auto cannon” job to keep track of things, and only run one migration at the time:
class MigrationAutoCannonJob < ApplicationJob
def perform
return unless migration_context.needs_migration?
if AsyncMigration.where(state: "processing").none?
AsyncMigration.create!(version: pending_migrations.first, state: "processing")
end
end
def pending_migrations
(migration_context.migrations.collect(&:version) - migration_context.get_all_versions)
end
# rest of the jobNow the job would create an entry in the async_migrations table but only when there are no other entries in “processing” state. That protects us from running more than one migration at the same time. Keep in mind that the job is not protected from races, but that’s OK because there will be only one instance of it scheduled.
Now let’s create a callback for the model to actually process the migration:
class AsyncMigration < ApplicationRecord
after_commit :enqueue_processing_job, on: :create
private
def enqueue_processing_job
MigrationProcessingJob.perform_later(async_migration_id: id)
end
endEach time AsyncMigration is created, it will enqueue MigrationProcessingJob that will run the actual migration. Let’s see how that job may look like:
class MigrationProcessingJob < ApplicationJob
def perform(params)
async_migration = AsyncMigration.find(params.fetch(:async_migration_id))
all_migrations = migration_context.migrations
migration = all_migrations.find { |m| m.version == async_migration.version }
# actual work!
ActiveRecord::Migrator.new(:up, [migration]).migrate
async_migration.update!(state: "finished")
end
def migration_context
ActiveRecord::Base.connection.migration_context
end
endThere’s quite a few things missing here, but you should get the idea by now: using a combination of two jobs and a database record, we can schedule migrations to run in background one by one.
Keep in mind that the code examples are very WIP. If you want to go further, you’d need to take care of these things:
- There’s no error handling. We might want to update a status of
AsyncMigrationwhen migration fails with an error - There’s no max retries defined for the job. Do you even want to retry migrations?
- You might want to measure and persist how much time the migration took
The possibilities are endless. You could even build an admin UI to run and monitor migrations, or send a message to a Slack channel when migrations complete or fail.
At Shopify we have hundreds of database shards, and on every schema change we have to run the migration on each of them. Release process would be way more fragile if those migrations were the part of deploy script. Instead, we use asynchronous migrations that would are eventually applied after each release. That’s one of the key features that allow us to release more than 50 times per day.
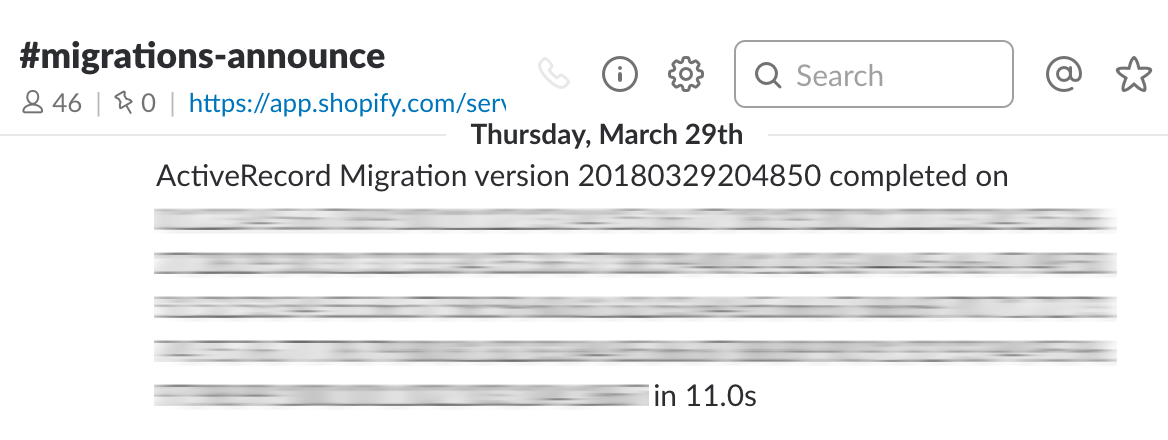
We even post status of migrations to a Slack channel.
If working on such things sounds exciting for you, come join my team at Shopify.
